Building a large database of MMA fight results I: scraping with rvest
29 Apr 2016While MMA is an exciting sport that offers many interesting data analysis opportunities, there is no existing dataset that has aggregated the results of the more than 400,000 fights that have occured to date. The challenge is not that the information is not available, rather that the information is distributed across thousands of webpages. If we are looking for individual fighters or MMA events, we can easily find a large amount of information about fighters and their fight histories.
For example, if we wanted to learn more about Andrei Arlovski we could look at his wikipedia page or any number of MMA-specific websites such as mixedmartialarts.com or sherdog.com.
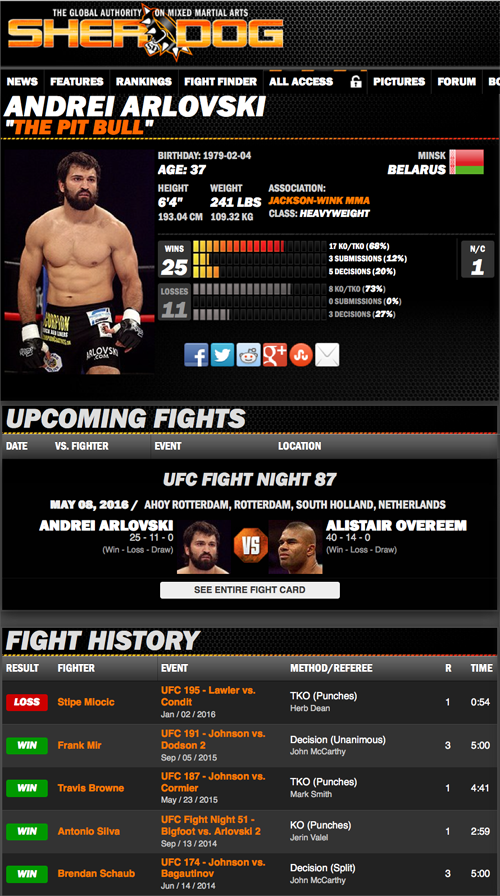
These websites, taking Sherdog as an example, provide a massive amount of factual data on fighters’ past performances. We can see Andrei’s age, weight, height as well as a list of his previous fights. Importantly, for each of these fights, we have the opponent’s name and a link to their corresponding webpage, so we could visit their webpage by following the link. We could follow the link to Arlovski’s most recent opponent, Stipe Miocic, as well as the links to Arlovski’s other opponents; determine their opponents in turn: and continue this iterative process until all fighters have been explored. Before we can implement this strategy, we need to be able to extract opponents’ links from individual webpages in addition to the fight information in which we are interested.
Extracting information from fighter pages using rvest
To make use of the information in web pages, we need to first specify the attributes that we are interested in extracting and then computationally extract these features.
Identifying common features of html can be challenging, but this process can be greatly simplified using CSS selectors like SelectorGadget. Selector gadget allows you to interactively select the parts of the html that you are interested in and the parts that you don’t want selected in order to generate a set of rules that guide the data extraction.
Extracting name and nickname
As an example, if we want to extract Arlovski’s name and nickname, then we can just click on his name and nickname and any fields that are extracted will be highlighted in green. If some fields are inappropriately selected (as shown below i.e., Andrei’s next fight in Ahoy Rotterdam), then these entries are then unselected and will be shown in red. From this input, SelectorGadget generates a minimal CSS selector that can then be used to extract name and nickname from Arlovski’s page or any other fighter’s page that we want to explore. For name and nickname this is: “.nickname em , .fn”.

Now that we have a CSS selector for name and nickname we need a way of programmatically extracting this information from webpages. To carry out this analysis, I will use the freely available programming language R. R is well-suited for streamlined data analysis due to its many user-created packages. One such package that will form the backbone of my analysis is rvest. I will also use dplyr and the %>% convention to simplify and improve the readability of my analysis.
The R code to extract name and nickname from Sherdog is:
# Load packages
library(rvest)
library(dplyr)
# read the webpage page of the fighter that we are interested in
fighter_page <- read_html("http://www.sherdog.com/fighter/Andrei-Arlovski-270")
fighter_page %>%
# use CSS selector to extract relevant entries from html
html_nodes(".nickname em , .fn") %>%
# turn the html output into simple text fields
html_text## [1] "Andrei Arlovski" "The Pit Bull"Extracting fight history and opponent links
Now that we have extracted some basic fields from html, we want to pull out some more substantial data by obtaining fight histories and links to all opponents. We can again use the CSS selector to identify the fight history section of the html. For Andrei Arlovski, this entry is “section:nth-child(4) td”
# Using our same fight page from before
fighter_table <- fighter_page %>%
# extract fight history
html_nodes("section:nth-child(4) td") %>%
# not a well-behaved table so it is extracted as strings
html_text() %>%
# wrap text to reform table
matrix(ncol = 6, byrow = T)
# Add column names from first entries of table
colnames(fighter_table) <- fighter_table[1,]
fighter_table <- fighter_table[-1,, drop = F]
fighter_table <- fighter_table %>%
as.data.frame(stringsAsFactors = F) %>% tbl_df() %>%
# reorder
select(Result, Fighter, `Method/Referee`, R, Time, Event)
kable(head(fighter_table, 10), row.names = F)| Result | Fighter | Method/Referee | R | Time | Event |
|---|---|---|---|---|---|
| loss | Alistair Overeem | TKO (Front Kick and Punches)Marc Goddard | 2 | 1:12 | UFC Fight Night 87 - Overeem vs. ArlovskiMay / 08 / 2016 |
| loss | Stipe Miocic | TKO (Punches)Herb Dean | 1 | 0:54 | UFC 195 - Lawler vs. ConditJan / 02 / 2016 |
| win | Frank Mir | Decision (Unanimous)John McCarthy | 3 | 5:00 | UFC 191 - Johnson vs. Dodson 2Sep / 05 / 2015 |
| win | Travis Browne | TKO (Punches)Mark Smith | 1 | 4:41 | UFC 187 - Johnson vs. CormierMay / 23 / 2015 |
| win | Antonio Silva | KO (Punches)Jerin Valel | 1 | 2:59 | UFC Fight Night 51 - Bigfoot vs. Arlovski 2Sep / 13 / 2014 |
| win | Brendan Schaub | Decision (Split)John McCarthy | 3 | 5:00 | UFC 174 - Johnson vs. BagautinovJun / 14 / 2014 |
| win | Andreas Kraniotakes | TKO (Punches)N/A | 2 | 3:14 | Fight Nights - Battle on NyamihaNov / 29 / 2013 |
| win | Mike Kyle | Decision (Unanimous)Dan Miragliotta | 3 | 5:00 | WSOF 5 - Arlovski vs. KyleSep / 14 / 2013 |
| loss | Anthony Johnson | Decision (Unanimous)Kevin Mulhall | 3 | 5:00 | WSOF 2 - Arlovski vs. JohnsonMar / 23 / 2013 |
| win | Mike Hayes | Decision (Unanimous)Valentin Tarasov | 3 | 5:00 | Fight Nights - Battle of Moscow 9Dec / 16 / 2012 |
We obtain links to opponents separately from the text fields but we can just as easily access these fields from the html using the CSS selector rule: “td:nth-child(2) a”
fighter_links <- fighter_page %>%
html_nodes("td:nth-child(2) a") %>%
html_attr("href")
fighter_links[1:5]## [1] "/fighter/Alistair-Overeem-461" "/fighter/Stipe-Miocic-39537" "/fighter/Frank-Mir-2329"
## [4] "/fighter/Travis-Browne-16785" "/fighter/Antonio-Silva-12354"Finding new fighters and large-scale extraction
Now that we can extract fight information and a list of opponents for any query fighters, this approach can be scaled to extract data from many fighters.
To do so, I started with a few initial fighters and as I evaluated these fighters, I kept track of all opponent links. Once the set of fighters I was processing was completed, I then compared already analyzed fighters to those in the list of potentially new fighters. This approach is easily implemented using a while loop. At this scale, querying html becomes computationally intensive (both for the user and server). Accordingly, only accessing a page every 1-5 seconds is generally advisable (or as otherwise indicated by the robots.txt).
From the above fight summaries, it is also clear that some of the raw data we obtained can be directly used (such as fight Results resulting in a win or loss) while other data (such as Method/Referee) needs to be unpacked so that we can make use of its information.
Expanding our search approach
One possibly unsatisfying aspect of searching for fighters based on their shared bouts is that while this approach will reach a set of fighters who are connected via fights, it may not explore all fighters. For example, female fighters may be totally disconnected from male fighters such that if we started with a male fighter we would get all (or most) male fighters while if we started with a female, we might only reach female fighters. From a network perspective (where fighters are nodes and fights are edges), the fight network may be composed of multiple disconnected subnetworks.
One obvious approach to dealing with the possibility of multiple disconnected sets of fighters would be to initialize our search using a fighter in each category. This may work for the major male and female subnetworks but if small pockets of fighters who have only fought one another exist, it would be difficult to identify these groups. If we care about such fighters, we can modify our fighter-to-fighter search strategy to search for fighters in additional ways. To more comprehensively comb through possible fighters, we can modify our search strategy to include both the events (e.g. UFC 195) which fighters competed in as well as the organizations (e.g. UFC) that these events occurred in. From organizations we can query additional events and from events we can query all fighters that were involved.
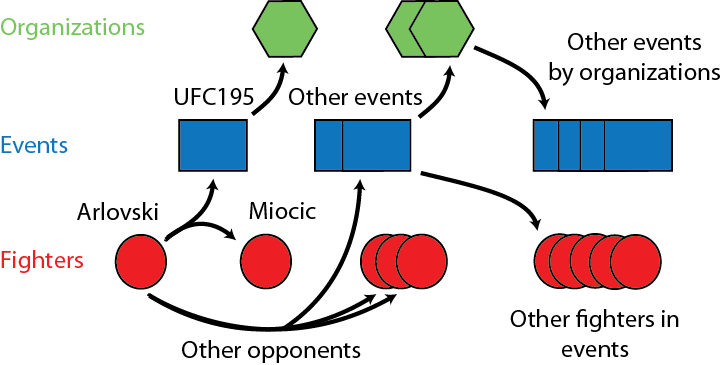
What did we get?
From scraping the Sherdog database, I obtained data from 143602 fighters encompassing 484061 fight entries. While I will leave deeper analysis of this dataset for future analyses, one aspect of this dataset that we can quickly observe is how many fights MMA fighters usually have.
library(ggplot2)
# bouts is a cleaned-up summary of this dataset (I will discuss its generation later on)
fight_counts <- bouts %>%
# count the number of each fighter's bouts
count(Fighter_link) %>%
rename(nfights = n) %>%
count(nfights)
# ggplot2 plotting theme
hist_theme <- theme(axis.title = element_text(color = "black", size = 25),
panel.background = element_rect(fill = "gray93"),
panel.border = element_rect(fill = NA, color = "black"),
panel.grid.minor = element_blank(),
panel.grid.major.x = element_blank(),
panel.grid.major.y = element_line(color = "gray70", size = 1),
axis.text = element_text(size = 18, hjust = 0.5, vjust = 0.5),
axis.ticks = element_line(size = 1),
axis.ticks.length = unit(0.15, "cm"))
no_sci_conv <- function(x){format(x, scientific=FALSE)}
ggplot(fight_counts, aes(x = nfights, y = n)) +
geom_point(color = "firebrick", size = 2) +
scale_y_continuous("Number of fighters", trans = "log10", breaks = 10^c(0:5), labels = no_sci_conv) +
scale_x_continuous("Number of fights", trans = "log10", breaks = c(1, 3, 10, 30, 100)) +
hist_theme
Looking at this log-log scatter plot of # of bouts in each fighter’s career, it is clear that the majority of fighters have very short careers. Only 9343 fighters have fought in more than 10 MMA bouts.
Another simple summary of the fight data that we can look at is when most of the fights in the data occurred.
ggplot(bouts, aes(x = Date)) +
geom_histogram(fill = "firebrick", bins = 2017-1990) +
scale_y_continuous("Number of bouts") +
scale_x_datetime("Fight Date", limits = as.POSIXct(c("1990", "2017"), format = '%Y')) +
hist_theme
By looking at when fights have occurred we can see the explosive growth of MMA, with the vast majority of fights occurring within the last 10 years.
In my next post, I will discuss some of the methods that I used to turn raw fighter-centric data into large tables. I will also talk about ways of standardizing the inputs so that fighters can be fairly compared.
- Share this on →


